
HtuPengyuyan
HtuPengyuyan
Java基础
第一个Java程序
开发体验—–Hello World
编写:
1 | // 创建一个java源文件:HelloWorld.java |
编译:
1 | javac HelloWorld.java |
运行:
1 | java HelloWord |
总结
java程序编写-编译-运行的过程
- 编写:我们将编写的java代码保存在以”.java”结尾的源文件中
- 编译:使用javac.exe命令编译我们的java源文件。格式:javac 源文件名.java
- 运行:使用java.exe命令解释运行我们的字节码文件。 格式:java 类名
② 在一个java源文件中可以声明多个class。但是,只能最多有一个类声明为public的。而且要求声明为public的类的类名必须与源文件名相同。
③ 程序的入口是main()方法。格式是固定的。
④ 输出语句:
System.out.println():先输出数据,然后换行;System.out.print():只输出数据;1
2
3
4
5
6
7
8
9
10
11
12
13
14
前者输出不换行,比如:
System.out.print("a");
System.out.print("b");
结果:
ab
后者输出后换行,比如:
System.out.println("a");
System.out.println("b");
结果:
a
b
⑤ 每一行执行语句都以;结束。
⑥ 编译的过程:编译以后,会生成一个或多个字节码文件。字节码文件的文件名与java源文件中的类名相同。
注释
注释:Comment
- 单行注释:
// 注释内容 - 多行注释:
/*注释内容 */ - 文档注释:
/**注释内容*/
作用
① 对所写的程序进行解释说明,增强可读性。方便自己,方便别人
② 调试所写的代码
特点
① 单行注释和多行注释,注释了的内容不参与编译。换句话说,编译以后生成的 .class 结尾的字节码文件中不包含注释掉的信息 ② 注释内容可以被JDK提供的工具 javadoc 所解析,生成一套以网页文件形式体现的该程序的说明文档。
③ 多行注释不可以嵌套使用
变量、标识符、保留字、变量
关键字与保留字
关键字(keyword)的定义和特点
定义:被 Java 语言赋予了特殊含义,用做专门用途的字符串(单词)
特点:关键字中所有字母都为小写
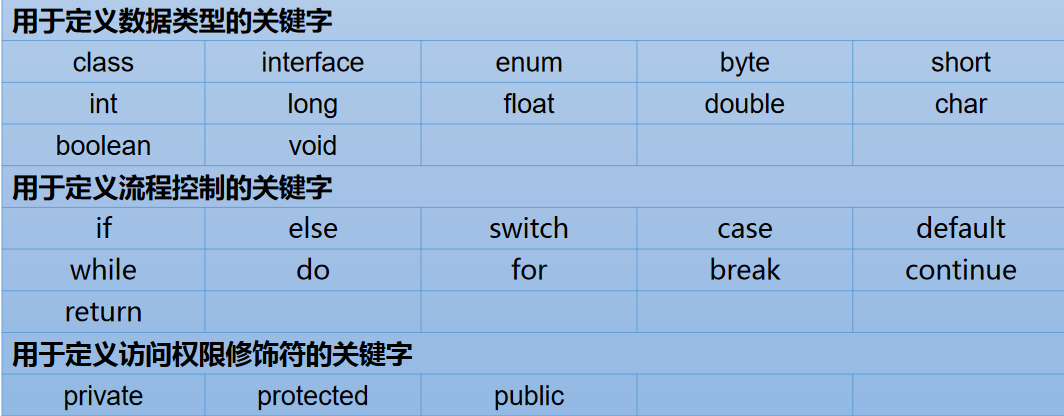
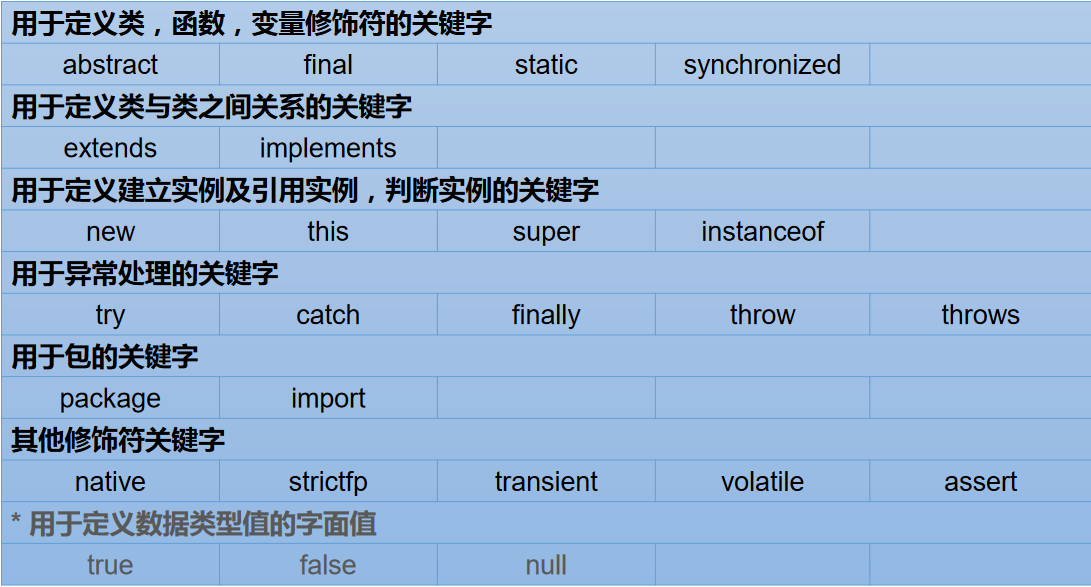
保留字
Java 保留字:现有 Java 版本尚未使用,但以后版本可能会作为关键字使用。自己命名标识符时要避免使用这些保留字goto、const。
标识符
定义
- Java 对各种变量、方法和类等要素命名时使用的字符序列称为标识符
- 技巧:凡是自己可以起名字的地方都叫标识符
定义合法标识符规则【重要】
- 由 26 个英文字母大小写,0-9,_或$ 组成
- 数字不可以开头。
- 标识符不能包含空格。
- 不可以使用关键字和保留字,但能包含关键字和保留字。
- Java 中严格区分大小写,长度无限制。
Java 中的名称命名规范
包名:多单词组成时所有字母都小写:xxxyyyzzz
类名、接口名:多单词组成时,所有单词的首字母大写:XxxYyyZzz
变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写:xxxYyyZzz
常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
注意 1:在起名字时,为了提高阅读性,要尽量有意义,“见名知意”。
注意 2:java 采用 unicode 字符集,因此标识符也可以使用汉字声明,但是不建议使用。
更多细节详见《代码整洁之道》
变量
变量的概念
- 内存中的一个存储区域;
- 该区域的数据可以在同一类型范围内不断变化;
- 变量是程序中最基本的存储单元。包含变量类型、变量名和存储的值。
变量的作用
- 用于在内存中保存数据。
使用变量注意:
- Java 中每个变量必须先声明,后使用;
- 使用变量名来访问这块区域的数据;
- 变量的作用域:其定义所在的一对{ }内;
- 变量只有在其作用域内才有效;
- 同一个作用域内,不能定义重名的变量;
基本数据类型
对于每一种数据都定义了明确的具体数据类型(强类型语言),在内存中分配了不同大小的内存空间。
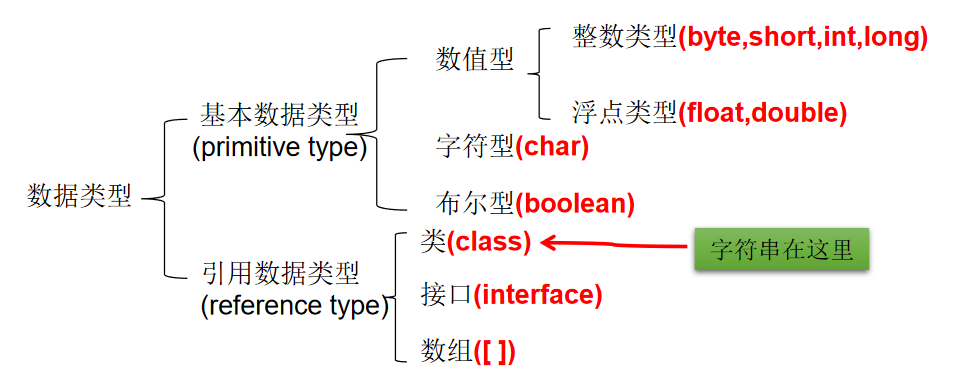
整数类型
- Java 各整数类型有固定的表数范围和字段长度,不受具体 OS 的影响,以保证 java 程序的可移植性。
- java 的整型常量默认为 int 型,声明 long 型常量须后加‘l’或‘L’
- java 程序中变量通常声明为 int 型,除非不足以表示较大的数,才使用 long
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| byte | 1字节=8bit位 | -128 ~ 127 |
| short | 2字节 | -2^15~ 2^15-1 |
| int | 4字节 | -2^31~ 2^31-1 (约21亿) |
| long | 8字节 | -2^63~ 2^63-1 |
1 | /* |
浮点类型
- 与整数类型类似,Java 浮点类型也有固定的表数范围和字段长度,不受具体操作系统的影响。
- 浮点型常量有两种表示形式:
- 十进制数形式:如:5.12 512.0f .512 (必须有小数点)
- 科学计数法形式:如:5.12e2 512E2 100E-2
- float:单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。
- double:双精度,精度是float的两倍。通常采用此类型。
- Java 的浮点型常量默认为double型,声明float型常量,须后加‘f’或‘F’
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| 单精度float | 4字节 | -3.403E38 ~ 3.403E38 |
| 双精度double | 8字节 | -1.798E308 ~ 1.798E308 |
字符类型
- char 型数据用来表示通常意义上“字符”(2字节)
- Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符。
- 字符型变量的三种表现形式:
- 字符常量是用单引号(‘ ’)括起来的单个字符。例如:char c1 = ‘a’; char c2 = ‘中’; char c3 = ‘9’;
- Java中还允许使用转义字符‘\’来将其后的字符转变为特殊字符型常量。例如:char c3 = ‘\n’; //’\n’表示换行符
- 直接使用Unicode值来表示字符型常量:‘\uXXXX’。其中,XXXX代表一个十六进制整数。如:\u000a 表示\n。
- char类型是可以进行运算的。因为它都对应有Unicode码。
1 | /* |
布尔类型:boolean
- boolean 类型用来判断逻辑条件,一般用于程序流程控制:
- if条件控制语句;
- while循环控制语句;
- do-while循环控制语句;
- for循环控制语句;
- boolean类型数据只允许取值true和false,无null。
- 不可以使用0或非0 的整数替代false和true,这点和C语言不同。
- Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false用0表示。———《java虚拟机规范8版》
1 | class VariableTest1{ |
基本数据类型转换
- 自动类型转换:容量小的类型自动转换为容量大的数据类型。数据类型按容量大小排序为:

- 有多种类型的数据混合运算时,系统首先自动将所有数据转换成容量最大的那种数据类型,然后再进行计算。
- byte,short,char之间不会相互转换,他们三者在计算时首先转换为int类型。
- boolean类型不能与其它数据类型运算。
- 当把任何基本数据类型的值和字符串(String)进行连接运算时(+),基本数据类型的值将自动转化为字符串(String)类型。
1 | /* |
强制类型转换
- 自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时要加上强制转换符:(),但可能造成精度降低或溢出,格外要注意。
- 通常,字符串不能直接转换为基本类型,但通过基本类型对应的包装类则可以实现把字符串转换成基本类型。
- 如:
String a = “43”; inti= Integer.parseInt(a); boolean类型不可以转换为其它的数据类型。
1 | short s = 5; |
运算符
分类
- 算术运算符
- 赋值运算符
- 比较运算符(关系运算符)
- 逻辑运算符
- 位运算符
- 三元运算符
算数运算符
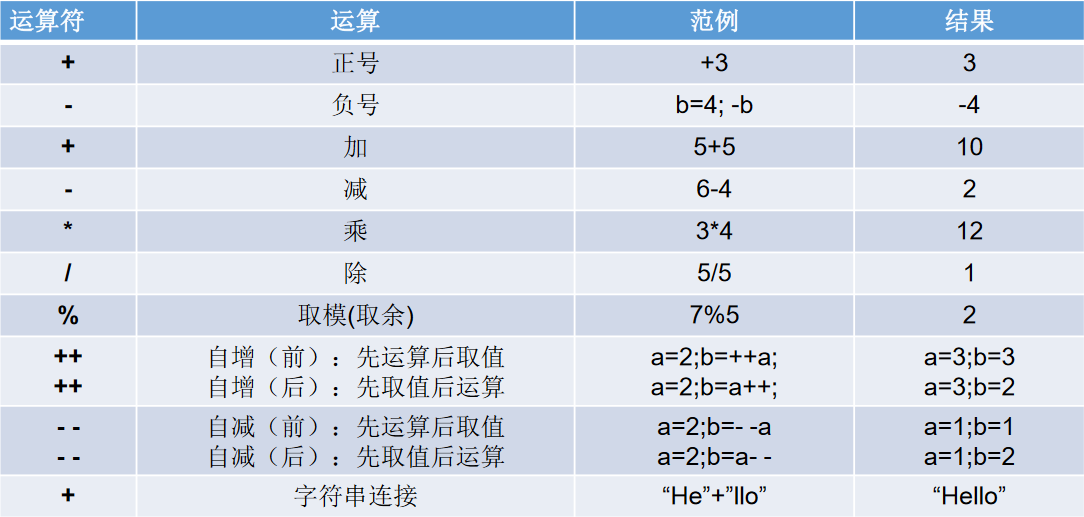
1 | /* |
算术运算符注意的问题
- 如果对负数取模,可以把模数负号忽略不记,如:5%-2=1。但被模数是负数则不可忽略。此外,取模运算的结果不一定总是整数。
- 对于除号“/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。例如:intx=3510;x=x/1000*1000; x的结果是?
- “+”除字符串相加功能外,还能把非字符串转换成字符串.例如:System.out.println(“5+5=”+5+5); //打印结果是 5+5=55 这里的+号起到连接作用
赋值运算
- 符号:
=- 当“=”两侧数据类型不一致时,可以使用自动类型转换或使用强制类型转换原则进行处理。
- 支持连续赋值。
- 扩展赋值运算符:
+=, -=, *=, /=, %=
1 | /* |
比较运算符
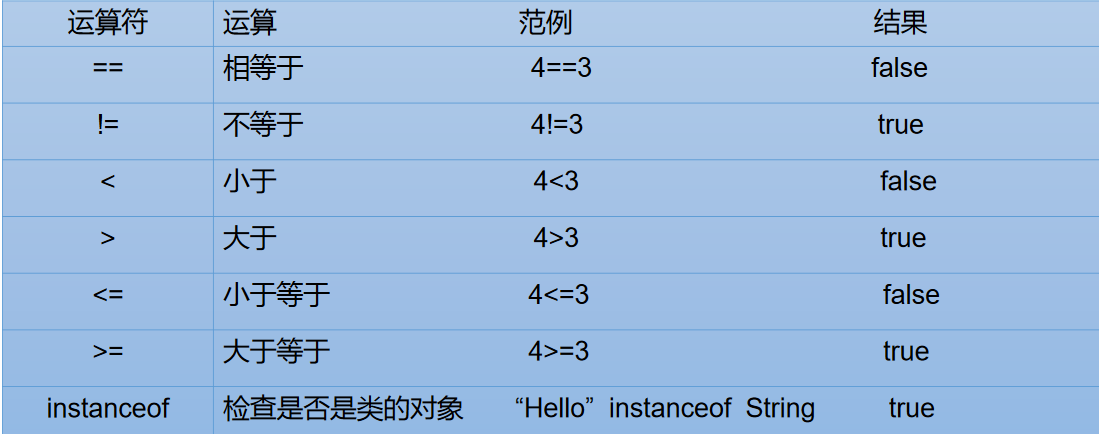
- 比较运算符的结果都是
boolean型,也就是要么是true,要么是false。 - 比较运算符“
==”不能误写成“=” 。
逻辑运算符
&—逻辑与|—逻辑或!—逻辑非&&—短路与||—短路或^—逻辑异或
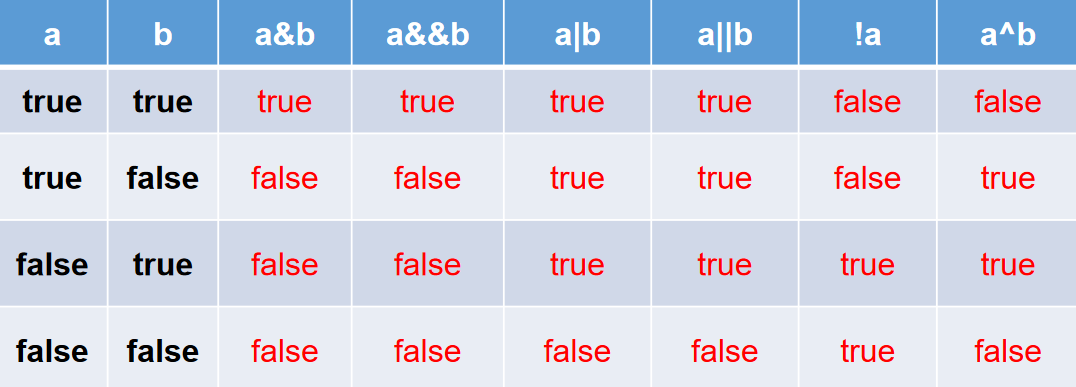
逻辑运算符用于连接布尔型表达式,在Java中不可以写成3<x<6,应该写成x>3 & x<6 。
“&”和“&&”的区别:
- 单&时,左边无论真假,右边都进行运算;
- 双&时,如果左边为真,右边参与运算,如果左边为假,那么右边不参与运算。
“|”和“||”的区别同理,||表示:当左边为真,右边不参与运算。
异或(^)与或( | )的不同之处是:当左右都为true时,结果为false。理解:异或,追求的是“异”!
练习
1 | /* |
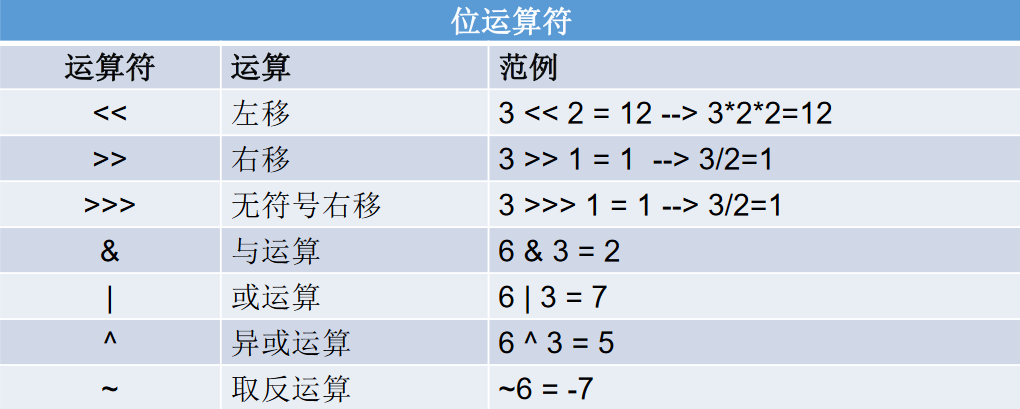
位运算符
三元运算符

1 | /* |
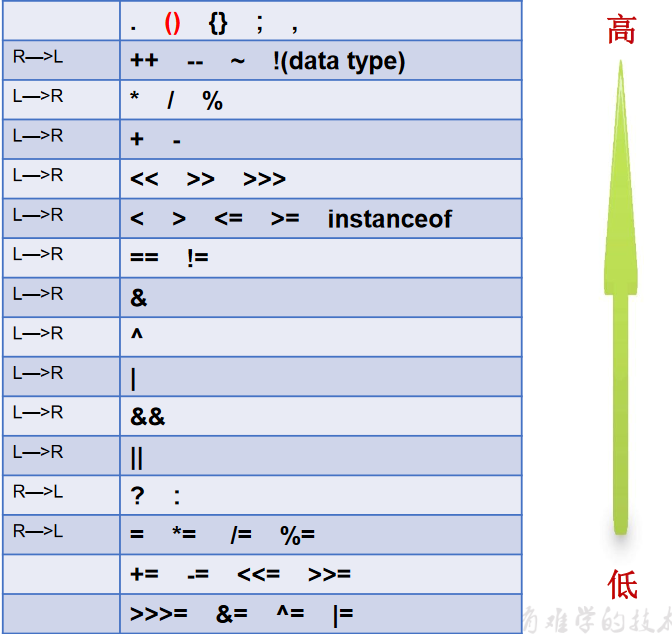
运算优先级
程序流程控制
概述
流程控制语句是用来控制程序中各语句执行顺序的语句,可以把语句组合成能完成一定功能的小逻辑模块。
分类
- 顺序结构
- 分支结构
- 循环结构
顺序结构
Java中定义成员变量时采用合法的前向引用

分支语句
if else
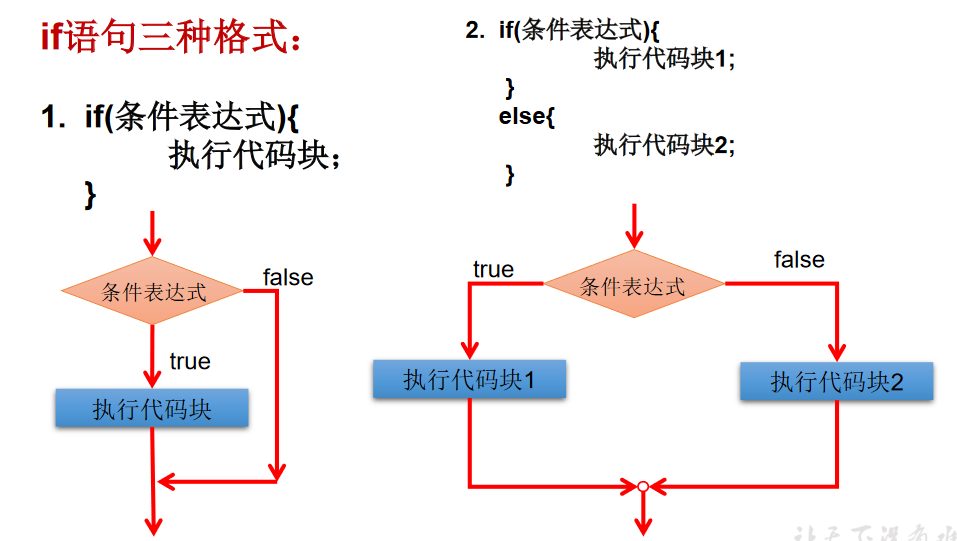
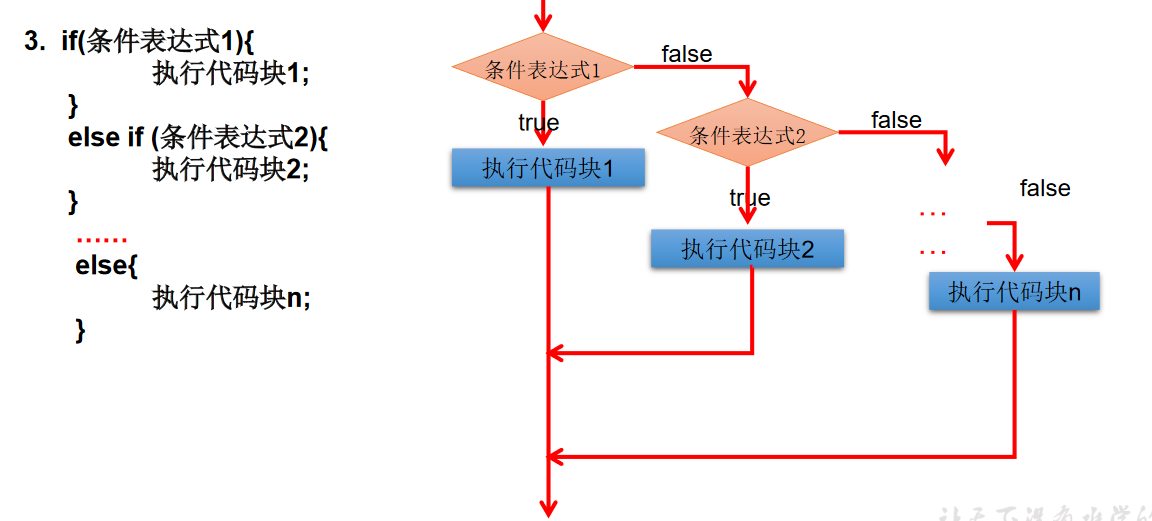
if-else使用说明:
条件表达式必须是布尔表达式(关系表达式或逻辑表达式)、布尔变量;
语句块只有一条执行语句时,一对{}可以省略,但建议保留;
if-else语句结构,根据需要可以嵌套使用;
当if-else结构是“多选一”时,最后的else是可选的,根据需要可以省略;
当多个条件是“互斥”关系时,条件判断语句及执行语句间顺序无所谓当多个条件是“包含”关系时,“小上大下/ 子上父下”。
1 | /* |
swich-case
注意: switch结构中的表达式,只能是如下的六种数据类型之一:
byte、short、char、int、枚举类型(JDK5.0)、String类型(JDK7.0)不能是:long,float,double,boolean。
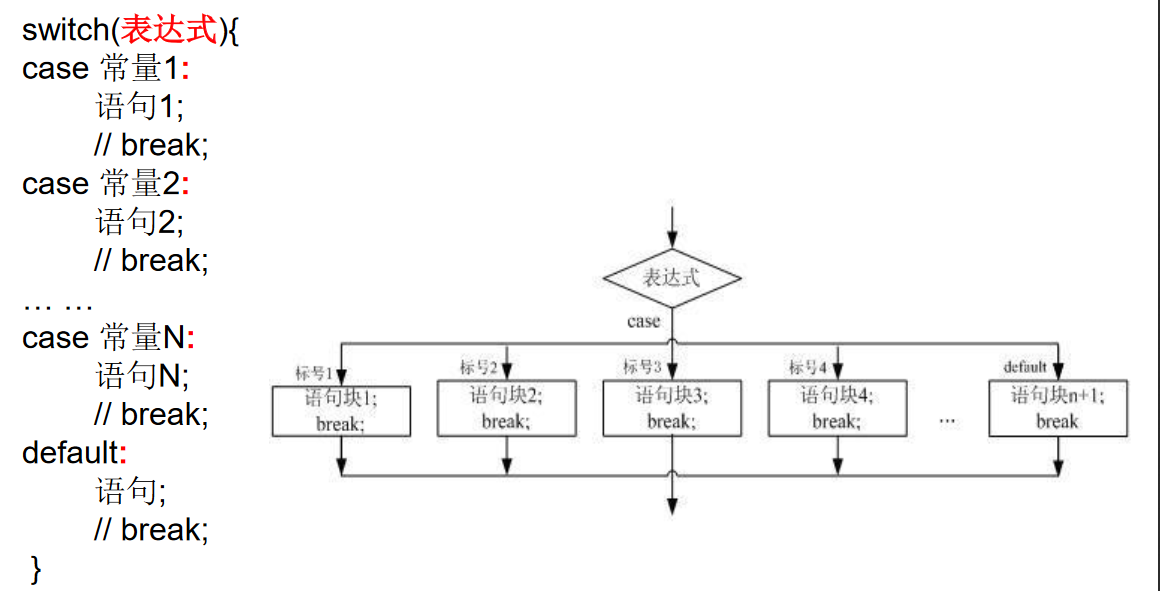
1 | /* |
输出语句
1 | /* |
1 | /* |
循环结构
循环结构
在某些条件满足情况下、反复执行特定代码的功能
循环语句分类
- for循环
- while循环
- do-while循环
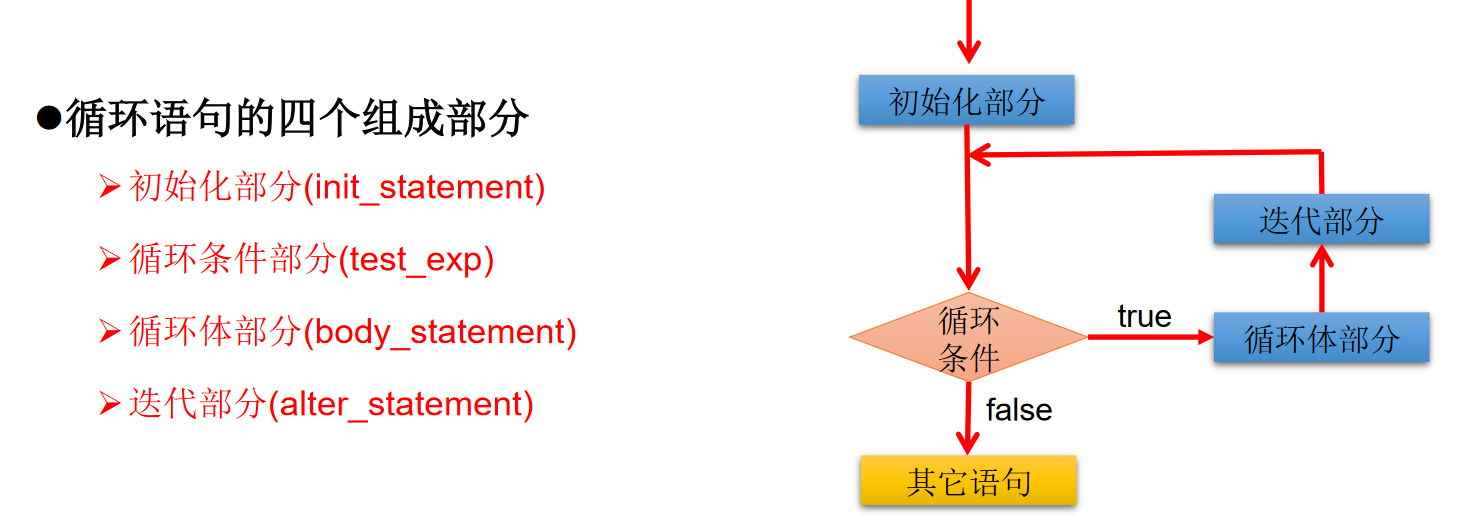
for 循环
1 | 语法格式 |
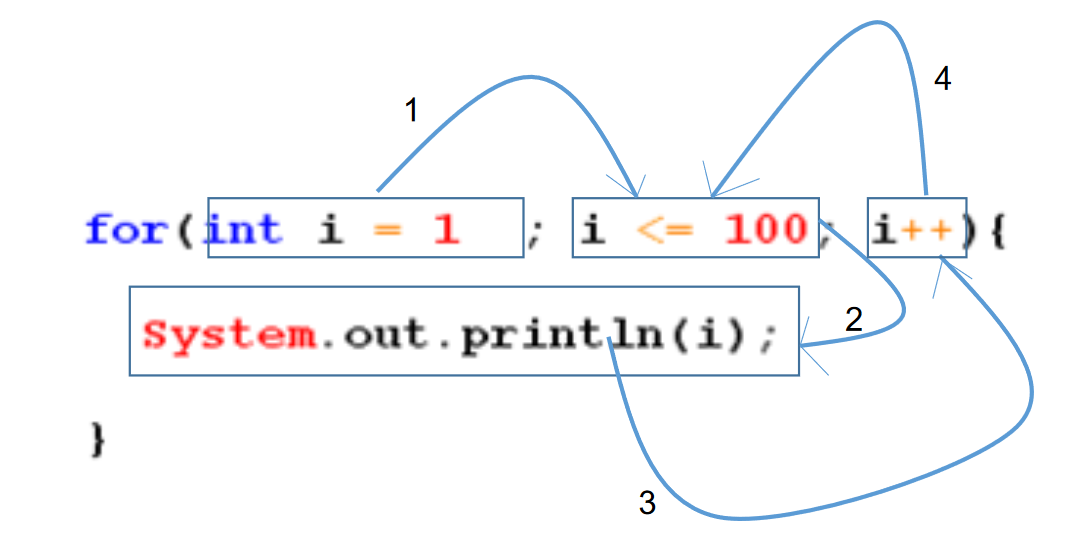
1 | /* |
while循环
语法格式
1 | ①初始化部分 |
说明
- 注意不要忘记声明④迭代部分。否则,循环将不能结束,变成死循环。
- for循环和while循环可以相互转换
1 | public class WhileLoop { |
练习
1 | /* |
do-while循环
1 | do-while循环结构的使用 |
练习1
1 | class DoWhileTest{ |
嵌套循环结构
嵌套循环
将一个循环放在另一个循环体内,就形成了嵌套循环。其中,for ,while ,do…while均可以作为外层循环或内层循环。
实质上,嵌套循环就是把内层循环当成外层循环的循环体。当只有内层循环的循环条件为false时,才会完全跳出内层循环,才可结束外层的当次循环,开始下一次的循环。
设外层循环次数为m次,内层为n次,则内层循环体实际上需要执行m*n次。
例题
- 九九乘法表
- 100以内的所有质数
练习1
1 | /* |
break、continue
1.break的使用
- break语句用于终止某个语句块的执行
1 | { |
- break语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块
1 | label1: { ...... |
continue
- continue 语句
- continue只能使用在循环结构中
- continue语句用于跳过其所在循环语句块的一次执行,继续下一次循环
- continue语句出现在多层嵌套的循环语句体中时,可以通过标签指明要跳过的是哪一层循环
return
- return:并非专门用于结束循环的,它的功能是结束一个方法。当一个方法执行到一个return语句时,这个方法将被结束。
- 与break和continue不同的是,return直接结束整个方法,不管这个return处于多少层循环之内。
说明
break只能用于switch语句和循环语句中。
continue 只能用于循环语句中。
二者功能类似,但continue是终止本次循环,break是终止本层循环。
break、continue之后不能有其他的语句,因为程序永远不会执行其后的语句。
标号语句必须紧接在循环的头部。标号语句不能用在非循环语句的前面。
很多语言都有goto语句,goto语句可以随意将控制转移到程序中的任意一条语句上,然后执行它。但使程序容易出错。Java中的break和continue是不同于goto的。
练习1
1 | /* |
数组
数组的概述
一、数组的概述
1.数组的理解:数组(Array),是多个相同类型数据按一定顺序排列的集合,
并使用一个名字命名,并通过编号的方式对这些数据进行统一管理。
2.数组的相关概念:
数组名
元素
角标、下标、索引
数组的长度:元素的个数
3.数组的特点:
1)数组属于引用类型的变量。数组的元素,既可以是基本数据类型,也可以是引用数据类型。
2)创建数组对象会在内存中开辟一整块连续的空间;
3)数组的长度一旦确定,就不能修改;
4)数组是有序排列的。
4.数组的分类:
① 按照维数:一维数组、二维数组、三维数组……
② 按照数组元素类型:基本数据类型元素的数组、引用类型元素的数组
一堆数组的使用
① 一维数组的声明和初始化- ② 如何调用数组的指定位置的元素
- ③ 如何获取数组的长度
- ④ 如何遍历数组
- ⑤ 数组元素的默认初始化值:见ArrayTest1.java
⑥ 数组的内存解析:见ArrayTest1.java
案例一 —ArrayTest.java
1 | public class ArrayTest { |
案例二–ArrayTest1.java
1 | /* |
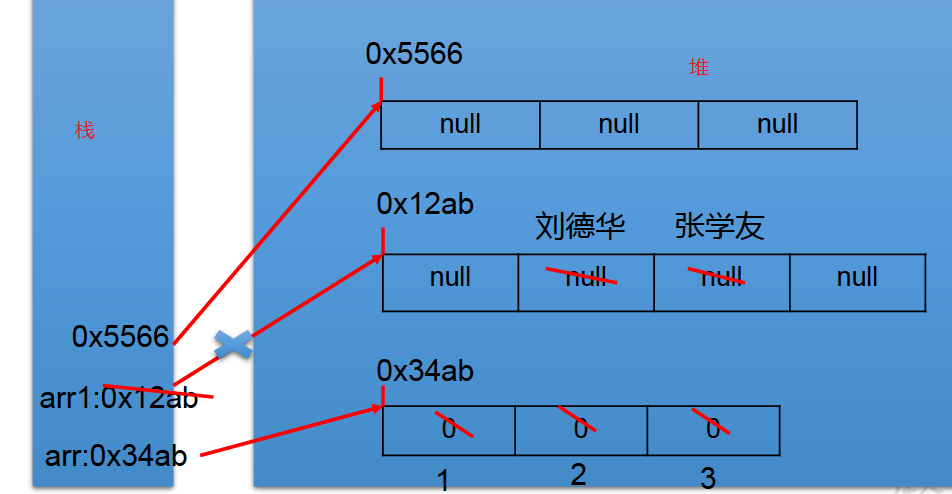
内存简化结构
一堆数组的内存解析
1 | int[] arr = new int[]{1,2,3}; |
练习
1 | /* |
1 | /* |
多组数组的使用
Java 语言里提供了支持多维数组的语法。
如果说可以把一维数组当成几何中的线性图形,那么二维数组就相当于是一个表格,像下图Excel中的表格一样。
二维数组
1 | /* |
1 | /* |
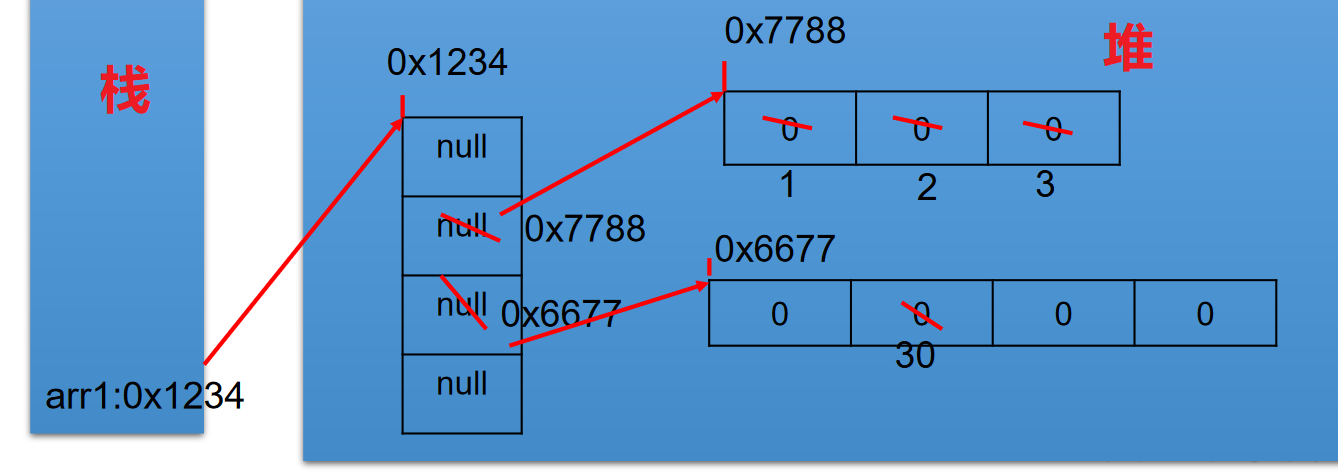
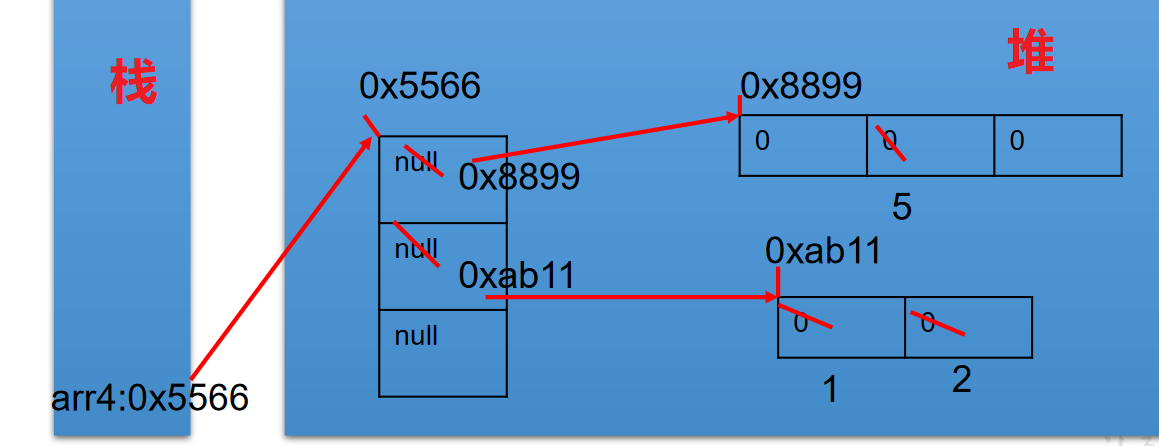
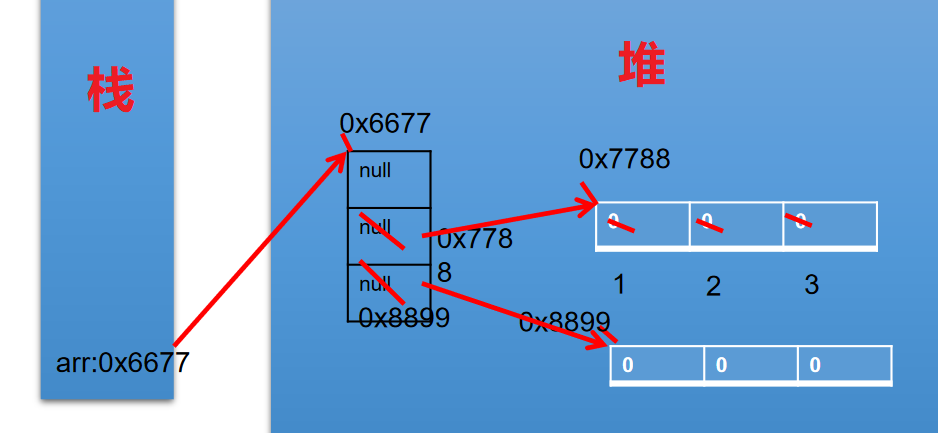
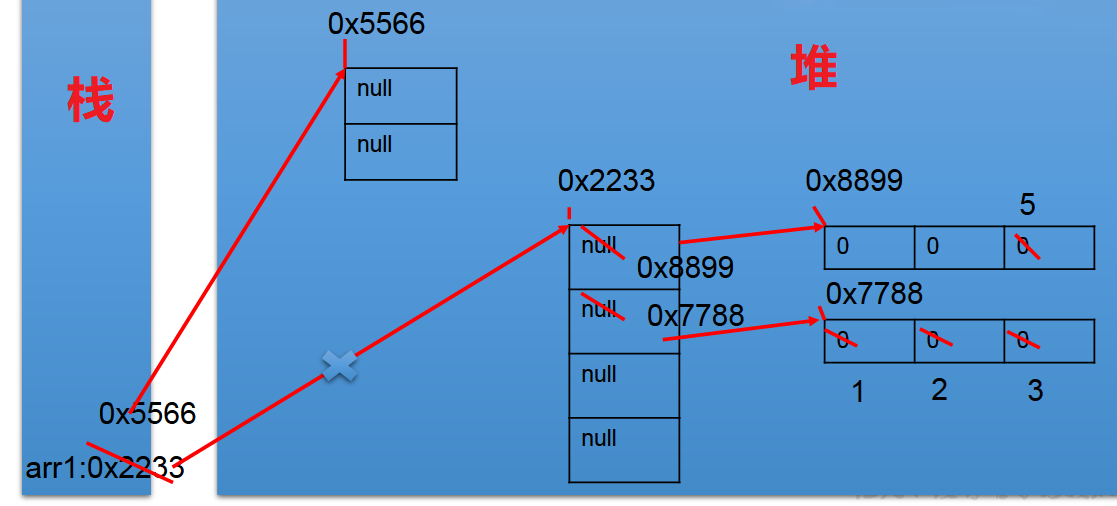
二维数组内存解析
1 | int[][] arr1 = new int[4][]; |
1 | int[][] arr4= newint[3][]; |
1 | int[][] arr = new int[3][]; |
1 | int[][] arr1= newint[4][]; |
面向对象
类和对象
- 三、面向对象的两个要素:
- 类:对一类事物的描述,是抽象的、概念上的定义
- 对象:是实际存在的该类事物的每个个体,因而也称为实 例(instance)。
- 可以理解为:类= 抽象概念的人;对象= 实实在在的某个人
- 面向对象程序设计的重点是类的设计;
- 设计类,其实就是设计类的成员。
Java类及类的成员
- 属性:对应类中的成员变量
- 行为:对应类中的成员方法

类与对象的创建及使用
1 | /* |
对象的创建和使用:内存解析
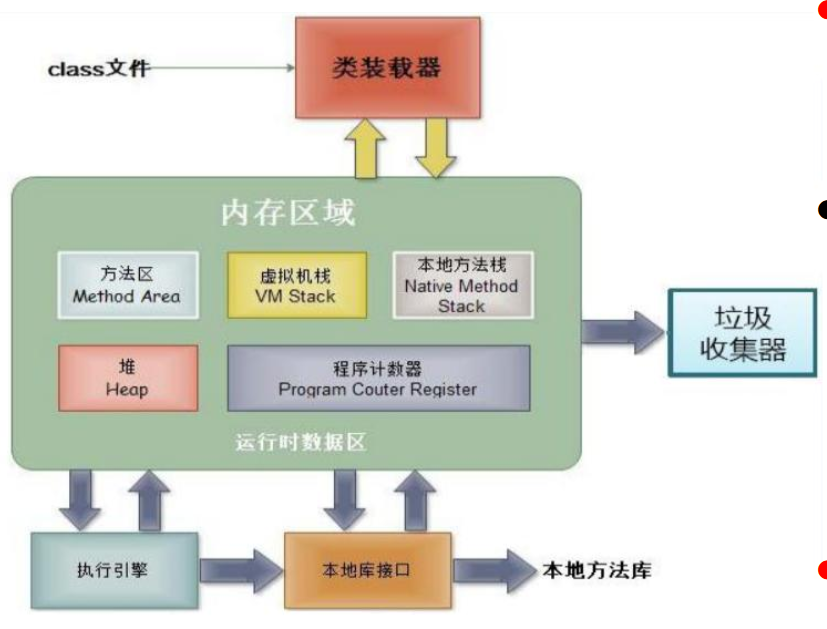
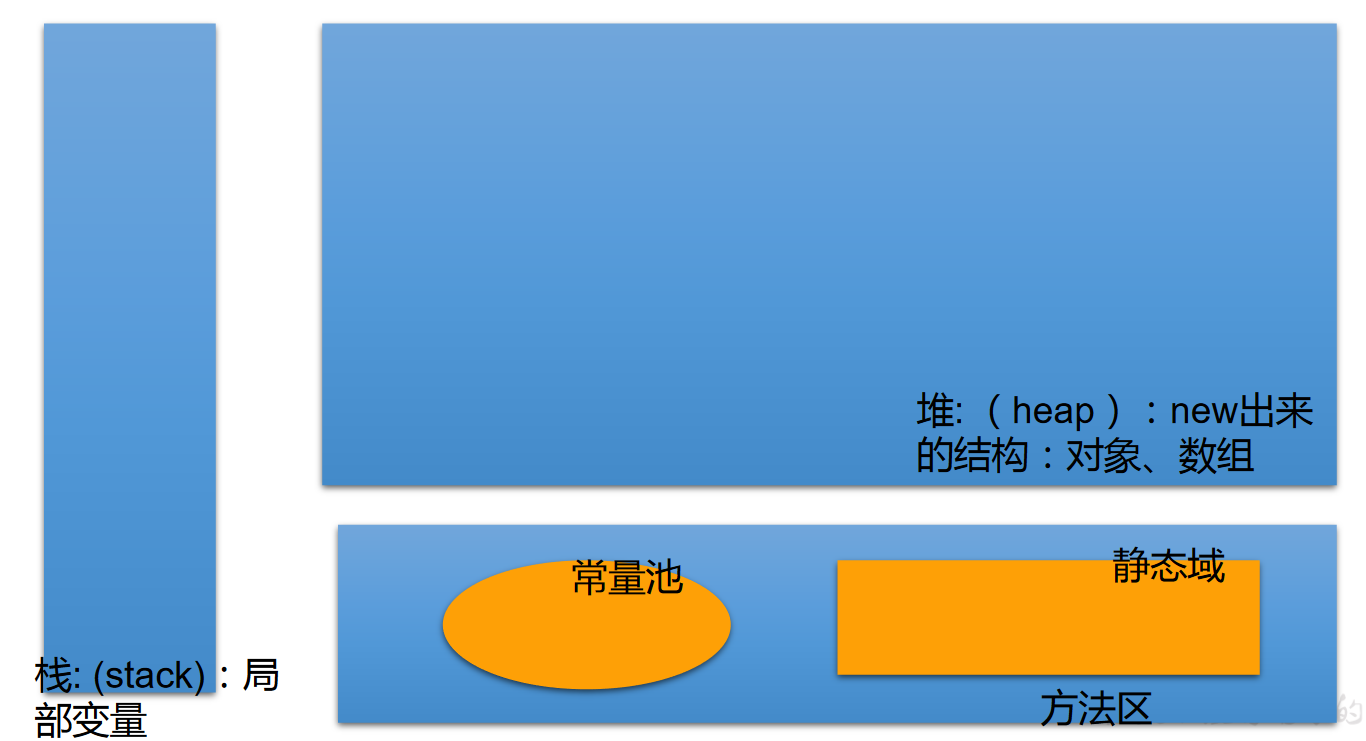
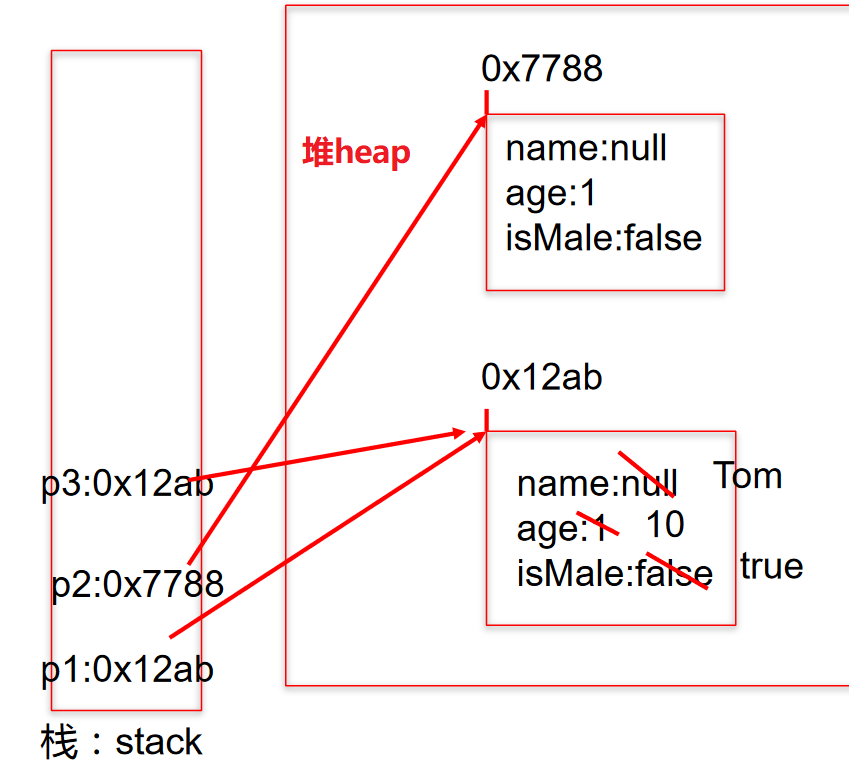
堆(Heap),此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。这一点在 Java 虚拟机规范中的描述是:所有的对象实例以及数组都要在堆上分配。
通常所说的栈(Stack),是指虚拟机栈。虚拟机栈用于存储局部变量等。局部变量表存放了编译期可知长度的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不等同于对象本身,是对象在堆内存的首地址)。方法执行完,自动释放。
方法区(MethodArea),用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
1 | Person p1= newPerson(); |
类的成员之一:属性
1 | /* |
类的成员之二:方法
1 | /* |
Promise
一、Promise的理解与使用
概念
Promise是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。
通俗讲,Promise是一个许诺、承诺,是对未来事情的承诺,承诺不一定能完成,但是无论是否能完成都会有一个结果。
- Pending 正在做。。。
- Resolved 完成这个承诺
- Rejected 这个承诺没有完成,失败了
Promise 用来预定一个不一定能完成的任务,要么成功,要么失败
在具体的程序中具体的体现,通常用来封装一个异步任务,提供承诺结果
Promise 是异步编程的一种解决方案,主要用来解决回调地狱的问题,可以有效的减少回调嵌套。真正解决需要配合async/await
特点
(1)对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:Pending(进行中)、Resolved(已完成,又称Fulfilled)和Rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。
(2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从Pending变为Resolved和从Pending变为Rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果。就算改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。
(3)支持链式调用,可以解决回调地狱的问题
用来解决回调地狱问题,但是只是简单的改变格式,并没有彻底解决上面的问题真正要解决上述问题,一定要利用promise再加上await和async关键字实现异步传同步
缺点
(1)无法取消Promise,一旦新建它就会立即执行,无法中途取消。和一般的对象不一样,无需调用。
(2)如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
(3)当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)
理解
- Promise 是一门新的技术(ES6 规范)
2)Promise 是 JS 中进行异步编程的新解决方案 备注:旧方案是单纯使用回调函数
从语法上来说: Promise 是一个构造函数
从功能上来说: promise 对象用来封装一个异步操作并可以获取其成功/ 失败的结果值
promise状态
a) promise 的状态
实例对象中的一个属性 『PromiseState』
- pending 未决定的
- resolved / fulfilled 成功
- rejected 失败
b) promise 的状态改变
- pending 变为 resolved
- pending 变为 rejected
说明:
只有这 2 种, 且一个 promise 对象只能改变一次无论变为成功还是失败, 都会有一个结果数据 成功的结果数据一般称为 value, 失败的结果数据一般称为 reason
异步编程
fs文件操作
1
require('fs').readFile('./index.html',(err,data)=>{})
数据库操作
AJAX
1
$.get('/server',(data)=>{})
定时器
1
setTimeout(()=>{},2000)
二、Promise常用API概述
Ⅰ- Promise 构造函数: Promise (excutor) {}
(1) executor 函数: 执行器 (resolve, reject) => {}
(2) resolve 函数: 内部定义成功时我们调用的函数 value => {}
(3) reject 函数: 内部定义失败时我们调用的函数 reason => {}
说明: executor 会在 Promise 内部立即
同步调用,异步操作在执行器中执行,换话说Promise支持同步也支持异步操作
Ⅱ-Promise.prototype.then 方法: (onResolved, onRejected) => {}
(1) onResolved 函数: 成功的回调函数 (value) => {}
(2) onRejected 函数: 失败的回调函数 (reason) => {}
说明: 指定用于得到成功 value 的成功回调和用于得到失败 reason 的失败回调 返回一个新的 promise 对象
Ⅲ-Promise.prototype.catch 方法: (onRejected) => {}
(1) onRejected 函数: 失败的回调函数 (reason) => {}
说明: then()的语法糖, 相当于: then(undefined, onRejected),内部是由then方法写的
(2) 异常穿透使用:当运行到最后,没被处理的所有异常错误都会进入这个方法的回调函数中
1 | let p = new Promise((resolve, reject) => { |
Ⅳ-Promise.resolve 方法: (value) => {}
(1) value: 成功的数据或 promise 对象
说明: 返回一个成功/失败的 promise 对象,直接改变promise状态
Ⅴ-Promise.reject 方法: (reason) => {}
(1) reason: 失败的原因
说明: 返回一个失败的 promise 对象,直接改变promise状态,
代码示例同上
Ⅵ-Promise.all 方法: (promises) => {}
promises: 包含 n 个 promise 的数组
说明: 返回一个新的 promise, 只有所有的 promise
都成功才成功, 只要有一 个失败了就直接失败
1 | let p1 = new Promise((resolve, reject) => { resolve('成功'); }) |
Ⅶ-Promise.race 方法: (promises) => {}
(1) promises: 包含 n 个 promise 的数组
说明: 返回一个新的 promise,
第一个完成的 promise 的结果状态就是最终的结果状态,如p1延时,开启了异步,内部正常是同步进行,所以
p2>p3>p1,结果是P2
1 | let p1 = new Promise((resolve, reject) => { |
改变Promise状态和指定回调函数谁先谁后
(1) 都有可能, 正常情况下是先指定回调再改变状态, 但也可以先改状态再指定回调
先指定回调再改变状态(异步):先指定回调–> 再改变状态 –>改变状态后才进入异步队列执行回调函数
先改状态再指定回调(同步):改变状态 –>指定回调 并马上执行回调
(2) 如何先改状态再指定回调? –>注意:指定并不是执行
① 在执行器中直接调用 resolve()/reject() –>即,不使用定时器等方法,执行器内直接同步操作
② 延迟更长时间才调用 then() –>即,在.then()这个方法外再包一层例如延时器这种方法
(3) 什么时候才能得到数据?
① 如果先指定的回调, 那当状态发生改变时, 回调函数就会调用, 得到数据
② 如果先改变的状态, 那当指定回调时, 回调函数就会调用, 得到数据
1 | let p = new Promise((resolve, reject) => { |
promise.then()返回的新 promise 的结果状态由什么决定?
(1) 简单表达: 由 then()指定的回调函数执行的结果决定
(2) 详细表达:
① 如果抛出异常, 新 promise 变为 rejected, reason 为抛出的异常
② 如果返回的是非 promise 的任意值, 新 promise 变为 resolved, value 为返回的值
③ 如果返回的是另一个新 promise, 此 promise 的结果就会成为新 promise 的结果
简单来说then返回的结果是新promise的结果
1 | let p = new Promise((resolve, reject) => { |
promise 如何串连多个操作任务?
(1) promise 的 then()返回一个新的 promise, 可以开成 then()的链式调用
(2) 通过 then 的链式调用串连多个同步/异步任务,这样就能用then()将多个同步或异步操作串联成一个同步队列
1 | let p = new Promise((resolve, reject) => { |
promise异常穿透
- 当使用 promise 的 then 链式调用时, 可以在最后指定失败的回调
- 前面任何操作出了异常, 都会传到最后失败的回调中处理
1 | let p = new Promise((resolve, reject) => { |
上面代码经过打断点发现在抛出错误后下一步执行catch
中断promise链
在关键问题2中,可以得知,当promise状态改变时,他的链式调用都会生效,那如果我们有这个一个实际需求:我们有5个then(),但其中有条件判断,如当我符合或者不符合第三个then条件时,要直接中断链式调用,不再走下面的then,该如何?
(1) 当使用 promise 的 then 链式调用时, 在中间中断, 不再调用后面的回调函数
(2) 办法: 在回调函数中返回一个 pendding 状态的promise 对象
1 | <script> |
三、Promise+async+await
axios是基于promise的一个http库,axios返回的就是一个Promise对象
Promise是最早提出的解决异步操作的一种解决方案, Promise对象是一个构造函数,用来生成promise实例,es6统一了它的用法。
1)Promise==>异步
2)await==>异步转同步
- await 可以理解为是 async wait 的简写。await 必须出现在 async 函数内部,不能单独使用。
- await 后面可以跟任何的JS 表达式。虽然说 await 可以等很多类型的东西,但是它最主要的意图是用来等待 Promise 对象的状态被 resolved。如果await的是 promise对象会造成异步函数停止执行并且等待 promise 的解决,如果等的是正常的表达式则立即执行
3)async==>同步转异步
- 方法体内部的某个表达式使用await修饰,那么这个方法体所属方法必须要用async修饰所以使用awit方法会自动升级为异步方法
4)mdn文档
Ⅰ-async函数
- 函数的返回值为 promise 对象
- promise 对象的结果由 async 函数执行的返回值决定
Ⅱ-await表达式
- await 右侧的表达式一般为 promise 对象, 但也可以是其它的值
- 如果表达式是 promise 对象, await 返回的是 promise 成功的值
- 如果表达式是其它值, 直接将此值作为 await 的返回值
Ⅲ-注意
- await 必须写在 async 函数中, 但 async 函数中可以没有 await
- 如果 await 的 promise 失败了, 就会抛出异常, 需要通过 try…catch 捕获处理
axios
自己创建一个APi
API的分类
REST API: restful (Representational State Transfer (资源)表现层状态转化)
(1) 发送请求进行CRUD 哪个操作由请求方式来决定
(2) 同一个请求路径可以进行多个操作
(3) 请求方式会用到GET/POST/PUT/DELETE
非REST API: restless
(1) 请求方式不决定请求的CRUD 操作
(2) 一个请求路径只对应一个操作
(3) 一般只有GET/POST
使用json-server搭建REST API
json-server是什么
用来快速搭建REST API 的工具包
使用json-server
- 在线文档: https://github.com/typicode/json-server
- 下载:
npm install -g json-server - 目标根目录下创建数据库 json 文件:
db.json
1 | { |
启动服务器执行命令: npx json-server --watch db.json
axios
介绍
- 文档: https://github.com/axios/axios
- 基于 xhr + promise 的异步 ajax请求库
- 浏览器端/node 端都可以使用
- 支持请求/响应拦截器
- 支持请求取消
- 请求/响应数据转换
- 批量发送多个请求
常用语法
axios(config): 通用/最本质的发任意类型请求的方式
axios(url[, config]): 可以只指定url 发get 请求
axios.request(config): 等同于axios(config)
axios.get(url[, config]): 发get 请求
axios.delete(url[, config]): 发delete 请求
axios.post(url[, data, config]): 发post 请求
axios.put(url[, data, config]): 发put 请求
axios.defaults.xxx: 请求的默认全局配置(method\baseURL\params\timeout…)
axios.interceptors.request.use(): 添加请求拦截器
axios.interceptors.response.use(): 添加响应拦截器
axios.create([config]): 创建一个新的axios(它没有下面的功能)
axios.Cancel(): 用于创建取消请求的错误对象
axios.CancelToken(): 用于创建取消请求的 token 对象
axios.isCancel(): 是否是一个取消请求的错误
axios.all(promises): 用于批量执行多个异步请求
axios.spread(): 用来指定接收所有成功数据的回调函数的方法
响应报文
响应报文分为四个部分:响应头、响应行、响应体、相应空行
使用axios访问测试
1 |
|
XHR 的 ajax 封装 (简单版axios)
特点
- 函数的返回值为
promise, 成功的结果为response, 失败的结果为error - 能处理多种类型的请求: GET/POST/PUT/DELETE
- 函数的参数为一个配置对象
1 | { |
使用测试
1 | // 1. GET请求:从服务器端获取数据 |
ESM与CommonJS模块化
前端模块化(CMJ与ESM)
1.为什么要模块化
- 把具有不同功能的板块封装为不同的模块,比如把涉及到网络请求的函数全都写在一个network.js文件里,把一些工具类的函数写在tool.js文件里,框架里的每一个组件都占据一个.vue文件,避免所有代码都写到一起,难以管理,同时还可以提高代码的复用率
- 通常一个文件就是一个模块,有自己的作用域,只向外暴露特定的变量和函数和类。
2.模块化规范
目前流行的js模块化规范有CommonJS、AMD、CMD以及ES6的模块系统
一、CommonJS
NodeJS是CommonJS规范的主要实践者,它有四个重要的环境变量为模块化的实现提供支持:module、exports、require、global。实际使用时,用**module.exports定义当前模块对外输出的接口(不推荐直接用exports),用require加载模块**。
1.NodeJS采用了CommonJS规范实现了模块系统
2.CommonJS规范
CommonJS规范规定了如何定义一个模块, 如何暴露(导出)模块中的变量函数, 以及如何使用定义好的模块
在CommonJS规范中一个文件就是一个模块
在CommonJS规范中每个文件中的变量函数都是私有的,对其他文件不可见的
在CommonJS规范中每个文件中的变量函数必须通过exports暴露(导出)之后其它文件才可以使用
在CommonJS规范中想要使用其它文件暴露的变量函数必须通过require()导入模块才可以使用
1.Node模块中暴露数据的几种方法
在学习Node中学习过现在大概复习了解一下
分为
exports xxx =和module.exports.xxxmodule.exports可以不通过对象的属性赋值,可以直接赋值
2.require的引入规则
- require导入模块时可以不添加导入模块的类型(模块的后缀名可以不写)
如果没有指定导入模块的类型, 那么会按照查找顺序依次查找.js .json .node文件
无论是三种类型中的哪一种, 导入之后都会转换成JS对象返回给我们
导入自定义模块时必须指定路径 - require除了可以导入”自定义模块(文件模块)“、还可以导入”系统模块(核心模块–nodejs自带的)”、“第三方模块(别人写的,可以直接使用)”
导入”自定义模块”模块时前面必须加上路径(就是前面的./之类的)
导入”系统模块”和”第三方模块”是不用添加路径 - 查找
如果是”系统模块”直接到环境变量配置的路径中查找
如果是”第三方模块”会按照module.paths数组中的路径依次查找
二、ES6Module(ESM)
ES6 在语言标准的层面上,实现了模块功能,而且实现得相当简单,旨在成为浏览器和服务器通用的模块解决方案。其模块功能主要由两个命令构成:
export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。在ES6之前,要使用一个模块,必须使用require函数将一个模块引入,但ES6并没有采用这种模块化方案,在ES6中使用import指令引入一个模块或模块中的部分接口,并没有将require写入标准,这也就是说require对于ES6代码而言,只是一个普通函数。
1
2
3
4
5
6
7
8
9
10
11/** 定义模块 math.js **/
var basicNum = 0;
var add = function (a, b) {
return a + b;
};
export { basicNum, add };
/** 引用模块 **/
import { basicNum, add } from './math';
function test(ele) {
ele.textContent = add(99 + basicNum);如上例所示,使用
import命令的时候,用户需要知道所要加载的变量名或函数名。其实ES6还提供了****export default命令,为模块指定默认输出,对应的import语句不需要使用大括号****。这也更趋近于AMD的引用写法。1
2
3
4
5
6
7
8
9/** export default **/
//定义输出
export default { basicNum, add };
//引入
import math from './math';
function test(ele) {
ele.textContent = math.add(99 + math.basicNum);ES6的模块不是对象,
import命令会被 JavaScript 引擎静态分析,在编译时就引入模块代码,而不是在代码运行时加载,所以无法实现条件加载。也正因为这个,使得静态分析成为可能。
export default具体使用
其实export default和export的功能是一样的,但是一个文件里面只能有一个export default语句。
export default是把所有{}中所有的内容都赋值给default,然后当我们导入的时候也可以改变名称,但是其实是把所有的default导入了
使用方式
使用liveserver打开
首先在使用上,唯一的区别就是需要在script标签上添加一个type="module"的属性来表示这个文件是作为module的方式来运行的。
1 | <script type="module"> |
然后在对应的module文件中就是经常会在webpack中用到的那样。
语法上并没有什么区别(本来webpack也就是为了让你提前用上新的语法:) )
message.js
1 | export default 'hello world' |
这里说一下为什么不能用浏览器直接打开而是需要open livesever
为什么会报错?
不会引起跨域的引入外部文件的就link标签,img标签,script标签,除开这三个,只要不符合同源策略(协议,域名,端口)就会引发跨域问题

解决方法:
通过搭建本地一个服务器去进行资源的问题来解决跨域问题
例如: 1.node 打开 2.phpStydy 打开
(50条消息) 在html中使用import遇到的问题_麦兜:)的博客-CSDN博客_html import
关于一些导入的用法
原生的ESModules import导入,后面不能省略,后缀名、不能省略index.js,必须以“./“或者”/“开始,相对和绝对路径,也可以直接使用连接完成的url。
1 |
|
在浏览器上使用原生的ESM
通过 script[type=module],可直接在浏览器中使用原生 ESM。这也使得前端不打包 (Bundless) 成为可能。
1 | <script type="module"> |
ImportMap
但 Http Import 每次都需要输入完全的 URL,相对以前的裸导入 (bare import specifiers),很不太方便,如下例:
1 | import lodash from "lodash"; |
在 ESM 中,可通过 importmap 使得裸导入可正常工作:
1 | <script type="importmap"> |
此时可与以前同样的方式进行模块导入
1 | import lodash from 'lodash' |
示例
1 | <script type="importmap"> |
分析import和require引入模块时不同用法
import作为es6引入模块的方法必须让引进时的script或者package.json加上 "type": "module"这一属性,直接看代码
index.js
1 | import _ from 'lodash' |
package.json
1 | { |
package.json应该是默认Commonjs语法所以不需要引入即可使用require
1 | var _ = require('lodash'); |
如果在"type": "module"下要使用require方法引入文件
在require前加上这两句话
这是由于从node.js 14版及以上版本中,require作为COMMONJS的一个命令已不再直接支持使用,所以我们需要导入createRequire命令才可以
1 | import { createRequire } from 'module'; |
探讨ES6的import export default 和CommonJS的require module.exports - 掘金 (juejin.cn)
j
title: webpack应用
date: 2022-11-29 16:49:56
tags:
基础使用
安装
首先使用npm init初始化项目,然后安装webpack以及webpack-cli
1 | // 全局安装 |
配置文件
在文件根目录下新建webpack.config.js配置文件
1 | const path = require('path') |
打包命令
使用本地环境进行打包输出
1 | npx webpack |
1 | npx webpack --watch // 自动生成 |
核心概念
Entry入口
指示Webpack以哪个文件为入口起点开始打包
Output输出
指示Webpack打包后的资源bundles输出到哪里,以及如何命名
1 | const path = require('path'); |
plugin插件
可以用于执行范围更广的任务。插件的范围包括,从打包优化和压缩,一直到重新定义环境中的变量等。
HtmlWebpackPlugin插件
基本用法
该插件将为你生成一个 HTML5 文件, 在 body 中使用 script 标签引入你所有 webpack 生成的 bundle。 只需添加该插件到你的 webpack 配置中,如下所示:
1 | const HtmlWebpackPlugin = require('html-webpack-plugin'); |
打包后会生成dist/index.html文件
1 |
|
如果你有多个 webpack 入口,他们都会在已生成 HTML 文件中的 <script> 标签内引入。
如果在 webpack 的输出中有任何 CSS 资源(例如,使用 MiniCssExtractPlugin 提取的 CSS),那么这些资源也会在 HTML 文件 <head> 元素中的 <link> 标签内引入。
devServer
在开发环境中,用于自动编译并自动刷新页面,方便开发过程中的调试。注:该功能只会在内存中编译打包,不会有任何文件输出,如需更新到生产环境中,还需重新打包代码。
安装
1 | npm i webpack-dev-server -D |
配置
在webpack.config.js文件中进行配置
1 | module.exports = { |
启动
1 | npx webpack-dev-server |
loader
webpack只能理解 JavaScript 和 JSON 文件,这是 webpack 开箱可用的自带能力。loader 让 webpack 能够去处理其他类型的文件,并将它们转换为有效 模块,以供应用程序使用,以及被添加到依赖图中。
warning
webpack的其中一个强大的特性就是能通过import导入任何类型的模块(例如.css文件),其中打包程序或任务执行器的可能并不支持。我们认为这种语言扩展时很有必要的,因为这可以使开发人员创建出更准确的依赖关系图
在webpack的配置中,loader有两个属性:
test属性,识别出哪些文件会被转换use属性,定义出在进行转换时,应该使用哪个loader
1 | const path = require('path'); |
以上配置中,对一个单独的 module 对象定义了 rules 属性,里面包含两个必须属性:test 和 use。这告诉 webpack 编译器(compiler) 如下信息:
“嘿,webpack 编译器,当你碰到「在 require()/import 语句中被解析为 ‘.txt’ 的路径」时,在你对它打包之前,先 use(使用) raw-loader 转换一下。”
chunk、bundle、moudel
module、chunk、bundle 这三个都可以理解为文件,区别在于:我们直接写出来的是 module,webpack 处理时是 chunk,最后生成浏览器可以直接运行的是 bundle。也可以这样理解,module,chunk 和 bundle 其实就是同一份逻辑代码在不同转换场景下的三个名字。
产生Chunk的三种途径
- entry入口
- 异步加载模块
- 代码分割(code spliting)
摘抄自Webpack 理解 Chunk - 掘金 (juejin.cn)
ChunkVSModule
Module
首先来说module,Webpack可以看做是模块打包机,我们编写的任何文件,对于Webpack来说,都是一个个模块。所以Webpack的配置文件,有一个module字段,module下有一个rules字段,rules下有就是处理模块的规则,配置哪类的模块,交由哪类loader来处理。
1 | module: { |
Chunk
Chunk是Webpack打包过程中,一堆module的集合。我们知道Webpack的打包是从一个入口文件开始,也可以说是入口模块,入口模块引用这其他模块,模块再引用模块。Webpack通过引用关系逐个打包模块,这些module就形成了一个Chunk。
资源模块Asset Modules
资源模块(asset module)是一种模块类型,它允许使用资源文件(字体,图标等)而无需配置额外 loader。
该方法需将资源在 JS 中通过 import 进行导入或css中进行导入
1 | // js 文件导入 |
资源模块类型
- asset/resource:发送一个单独的文件并导出 URL
- asset/inline:导出一个资源的 Data URI ( 64位图 )
- asset/source:导出资源的源代码
- asset:在导出一个资源的 Data URI 和发送一个单独的文件之间自动进行选择
详情看webpack中文文档[webpack文档](webpack 中文文档 (docschina.org))
resourse,inline,source示例
(解析)[(50条消息) Webpack5资源配置(三)_xiaojian044的博客-CSDN博客_asset/inline]
asset/recource资源:发送一个单独的文件
asset/inline资源:inline这个资源类型用于导出一个资源的data url ,在webpack.config.js中
asset/source资源:导出资源的源代码 ,在webpack.config.js中module.rules中配置:
sset通用资源类型:在导出一个资源的 Data URI 和发送一个单独的文件之间自动进行选择,
webpack按照默认条件,自动的在recource资源和inline资源之间进行选择,小于8kb的文件,将会
视为inline模块类型,否则会被视为resource模块类型,可以通过webpack配置的module rule层级
中,设置rules.parser.dataUrlCondition选项来修改此条件
module.rules中配置:
1 | const path = require('path') |
asset示例
1 | module.exports = { |
index.js
1 | import helloword from "./02.index"; |
Source Map
一种提供源代码到构建后代码映射的技术,如果构建后代码出错了,通过映射关系可以追踪源代码的错误。在 webpack.config.js 文件中配置
1 | module.exports = { |
- source-map:生成外部文件,错误代码的准确信息和源代码的错误位置
- inline-source-map:内联,错误代码的准确信息和源代码的错误位置。在代码底部生成,构建速度比外部文件更快
- hidden-source-map:生成外部文件,错误代码的原因,没有错误位置,无法追踪源代码错误。
- eval-source-map:内联,错误代码的准确信息和源代码的错误位置。每一个文件都生成对应的 source-map
- nosources-source-map:生成外部文件,
- cheap-source-map:生成外部文件,错误代码的准确信息和源代码的错误位置。只精确到行
- cheap-module-source-map:同 cheap-source-map,会将 loader 的 source map 加入
开发环境建议
- eval-source-map
- eval-cheap-module-source-map
生产环境建议
- source-map
- nosources-source-map
- hidden-source-map
资源处理
HTML资源
打包HTML
下载html-webpack-plugin插件
1
2npm i html-webpack-plugin - D
在 webpack.config.js 文件中引入插件并调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 引用插件
const HtmlWebpackPlugin = require('html-webpack-plugin')
module.exports = {
...
plugins: [
// 打包 HTML 文件
new HtmlWebpackPlugin({
// 指定 HTML 模版文件
template: './index.html',
// 指定 Script 标签位置
inject: 'body'
})
]
}- Webpack 会在输出目录中新创建一个 HTML 文件,在原始的 HTML 文件中无需引入 JS 文件,通过 Webpack 编译后的 HTML 文件会自动引入。
样式资源
打包css资源
下载样式处理解析器css-loader与style-loader
1 | npm i css-loader style-loader -D |
在配置文件中添加解析器
1 | module.exports = { |
在 JS 文件中导入 CSS 文件
1 | import '../css/main.scss' |
抽离css代码为独立文件
(正确解析)[(50条消息) webpack5之loader配置(四)_xiaojian044的博客-CSDN博客_webpack5 html-loader]
下载插件mini-css-extract-plugun
1 | npm i mini-css-extract-plugin -D |
引入插件
1 | const MiniCssExtractPligin = require('mini-css-extract-plugin') |
在plugins中引入
1 | plugins: [ |
修改rules的配置对象(删除’style.loader’,修改为[MiniCssExtractPligin.loader)
1 | { |
CSS 代码压缩(生产模式)
安装插件css-minimizer-webpack-plugin
1 | npm i css-minimizer-webpack-plugin -D |
在配置文件中进行配置
1 | const CssMinimizerPlugin = require("css-minimizer-webpack-plugin") |
- 压缩css代码,仅在生产模式下有效
CSS兼容性处理
下载postcss-loader,postcss,postcss-preset-env模块
1 | npm i postcss-loader postcss postcss-preset-env -D |
在根目录下创建postcss.config.js文件并进行配置
1 | module.exports = { |
引用模块
1 | const MiniCssExtractPlugin = require('mini-css-extract-plugin') |
postcss-preset-env 帮助 postcss 找到 package.json 中 browserslist 里的配置,通过配置加载指定的 css 兼容性
1 | // 在 package.json 中添加浏览器列表 |
图片资源
下载图片资源处理器
1 | npm i url-loader file-loader html-loader -D |
字体资源
通过CSS引入字体资源
1 | @font-face { |
在 webpack.config.js 文件中进行配置
1 | module.exports = { |
js资源
语法检查
使用 eslint 扫描我们所写的代码是否符合规范,严格意义上来说,eslint 配置跟 webpack 无关,但在工程化开发环境中,他往往是不可或缺的。
安装
1 | npm i eslint -D |
创建配置文件,根据提示选择需要的类型。配置完成后,将在 node_modules 文件夹中生成一个 .eslintrc.json 文件,将文件复制到根目录下。
1 | npx eslint --init |
会出来如下选择
1 | Need to install the following packages: |
JS 兼容处理
将 ES6 代码转换为低版本 ES5 代码
安装模块
- babel-loader: 在 webpack 里应用 babel 解析 ES6 的桥梁
- @babel/core: babel 核心模块
- @babel/preset-env: babel 预设,一组 babel 插件的集合
1 | npm i babel-loader @babel/core @babel/preset-env -D |
在 package.json 中配置
1 | module.exports = { |
regeneratorRuntime
regeneratorRuntime 是 webpack 打包生成的全局辅助函数,由 babel 生成,用于兼容 async/await 的语法
安装
1 | npm i @babel/runtime @babel/plugin-transform-runtime -D |
使用
1 | module.exports = { |
js压缩
安装插件terser-webpack-plugin
1 | npm i terser-webpack-plugin -D |
配置
1 | const TerserWebpackPlugin = require("terser-webpack-plugin") |
代码分离
代码分离是 webpack 中最引人瞩目的特性之一,可将代码分离到不同的文件中,然后将这些文件按需加载或并行加载,同时还可以获取代码加载的优先级。
方法1:入口起点(不推荐)
使用entry配置手动分离代码,如果多个入口共享的文件,会分别在每个包里重复打包
1 | module.exports = { |
方法2:防止重复
使用 Entry dependencies 或者 SplitChunksPlugin 去重和分离代码
1 | module.exports = { |
动态导入
async-module.js
1 | function getComponent() { |
两个重要的应用:懒加载 预加载
懒加载
指的是 JS 文件的懒加载,当事件触发或条件满足后才进行加载。是很好的优化网页或应用的方法。这种方法实际上是先把代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或即将引用一些新的代码块。这样加快了应用的初始加载速度,减轻总体体积,因为某些代码块可能永远不会被加载。
1 | document.querySelector('button').addEventListener('click', () => { |
** 这两个斜杠为魔法注释(/ *webpackChunkName: ‘filename’ */) **
预加载
等其他资源加载完毕后再进行加载,当事件触发或条件满足后,才会执行。兼容性较差,只能在pc端高版本浏览器中使用,手机端浏览器兼容较差。
1 | document.querySelector('button').addEventListener('click', () => { |
sliptChunks 插件
1 | module.exports = { |
缓存(生产模式)
使用hash值为文件命名
1 | module.exports = { |
缓存第三方库
将第三方库(library)(例如loadash)提取到单独的vendor.chunk文件中,是比较推荐的做法,这是因为它们很少像本地源代码那样频繁的修改,因此通过实现以上步骤,利用client的长效缓存机制,命中缓存来消除请求,并减少向server获取资源,同时还能保证client代码和server代码版本一致
1 | module.exports = { |
优化
公共路径publicPath
publicPath 配置公共路径,所有文件的引用将自动添加公共路径的绝对地址。
1 | module.exports = { |
环境变量 Environment variable
环境变量可以消除 webpack.config.js 在开发环境和生产环境之间的差异
1 | module.exports = ( env ) => { |
打包命令时如果使用生产模式,则在命令后增加:
1 | npx webpack --env production |
使用TerserPlugin压缩js文件
安装
1 | npm i terser-webpack-plugin -D |
引入
1 | const TerserPlugin = require('terser-webpack-plugin') |
配置
1 | // 压缩css代码块 |
拆分配置文件
目前,生产环境和开发环境使用的是一个配置文件,我们需要将这两个文件单独放到不同的配置文件中。如:webpack.config.dev.js(开发配置环境),webpack.config.prod.js(生产配置环境)/在项目根目录下创建一个配置文件夹config来存放他们
启动
1 | npx webpack -c ./config/webpack.config.prod.js |
webpack.config.dev.js
1 | const path = require('path') |
webpack.config.prod.js
1 | const path = require('path') |
使用merge进行拆分
安装merge
1 | npm install webpack-merge -D |
将公共的内容放到webpack.config.common.js
1 | const path = require('path') |
development.config
1 |
|
producton.config
1 |
|
合并的merge.config
1 | const { merge } = require('webpack-merge') |
devServer使用
配置代理
详细看vue
historyApiFallback
-如果我们的应用是个SPA(单页面应用),当路由到/some时(可以直接在地址栏里输入),会发现此时刷新页面后,控制台会报错
1 | GET http://localhost:300/some 404(Not Found) |
此时打开network刷新并查看,就发现了问题所在—浏览器把这个路由当作了静态资源地址去请求,然而我们并没有打包出/some这样的资源,所以这个歌访问无疑是404,如何解决他,这种时候,我们可以通过配置项来提供页面代替任何404的静态资源响应:
1 | module.exports={ |
此时重启服务器刷新后变成了index.html。当然,在多数业务场景下,我们需要根据不同的访问路径定制替代页面,这种情况下,我们可以使用rewrites这个配置项。类似这样:
1 | module.exports={ |
开发服务器主机
如果你在开发环境中起了一个devServer服务,并期望你的同事访问到它,你只需要配置:
```js
module.exports={
// ..
devServer:{
host:’0.0.0.0’
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-
## '@'来便捷解析路径
```js
const path = require('path')
module.exports={
mode:'development',
entry:'./src/app.js',
resolve:{
alias:{
'@':path.resolve(_dirame,'./src')
}
}
}
在其他需要引用路径时可以使用@替代
依赖图
安装工具
1 | npm i webpack bundle analyzer |
引入插件
1 | const {BundleAnalyzerPlugin}=require('webpack-bundle-analyzer') |
Vue-cli与Webpack之间的联系
vue-cli 里面包含了webpack, 并且配置好了基本的webpack打包规则,
lodash
一、简介
Lodash 是一个一致性、模块化、高性能的 JavaScript 实用工具库。
二、为什么选择Lodash?
- Lodash 通过降低 array、number、objects、string 等等的使用难度从而让 JavaScript 变得更简单。 Lodash 的模块化方法 非常适用于:
- 遍历 array、object 和 string
- 对值进行操作和检测
- 创建符合功能的函数
三、安装Lodash
1 | npm i -save lodash |
Node.js
1 | // Load the full build. |
四、常用lodash方法总结
数组
1._.chunk(array, [size=1]) “数组切割”
将数组(array)拆分成多个 size 长度的区块,并将这些区块组成一个新数组。 如果array 无法被分割成全部等长的区块,那么最后剩余的元素将组成一个区块。
1 | // => [['a', 'b'], ['c', 'd']] |
less
初始less
less作为一门CSS扩展语言,也就是说CSS预处理器。(Leaner Style Sheets)简称less,它只不过是为css新增这些的功能,比如说:变量、函数、作用域等等。它的优点是:更具有维护性、扩展性等,可以降低了维护的成本,根据按这样的话,那么less可以让我们写更少的代码做更多的事情。
和css相比下,css的语法非常简单,而且对开发者来说要求比较低,比较合适小白者,但是遇到有些问题,比如没有这种变量、函数等等,的确还不如less的扩展性,需要写大量的代码,但是看眼中的确没有逻辑的代码,CSS冗余度是比较高的。不方便维护,不利于复用,而且没有计算的能力。
如果对css有基础的话,less很容易上手的。因为css和less区别不大的,反正可以通过编译生成浏览器能识别的css文件。
less使用
可以进行嵌套
1 | .contain{ |
生成变量
@变量名:变量值;
@color:#fff+#111
1 | @nice-blue: #5B83AD; |
转换后的css
1 | li a{ |
less运算
- 乘号(*)和除号(/)的写法
- 运算符中间左右有个空格隔开1px + 5
- 对于两个不同单位的值进行运算,运算结果的值取第一个值的单位
- 如果两个值只有一个值有单位,则运算结果就取该单位
1
width:82rem/15px // 单位为rem
rem布局
rem布局
em和rem的认识
em: 相对于当前父元素的字体大小>>>1em=父元素标签的font-size
rem: 相对于根元素(html)的字体大小>>>html标签的font-size(浏览器默认的font-size的大小为16px)
rem布局的效果:
- 屏幕越大,标签就越大
- 屏幕越小,标签就越小
rem布局的原理:
通过媒体查询的方式动态改变html标签的font-size的大小
- 当屏幕越大,让html标签的font-size变大即可
- 当屏幕越小,让html标签的font-size变小即可
媒体查询
- 使用 @media 查询,你可以针对不同的媒体类型定义不同的样式。
1
2
3
4
5
6
7//语法
<style>
@media mediatype and|not|only (media feature) {
CSS-Code;
}
</style> - mediatype:媒体类型,包含(all,print,screen,speech)
1.all–所有设备
2.print–打印机和打印预览
3.screen–电脑屏幕,平板电脑,智能手机等
4.屏幕阅读器等发声设备
广泛使用的是all和screen
@media 可以针对不同的屏幕尺寸设置不同的样式,特别是如果你需要设置设计响应式的页面,@media 是非常有用的。
1 | <style> |
使用方法
引入css文件
1
2
3
4
5
6//通过mdeia指定媒体类型来实现区别引入css文件
<link rel="stylesheet" href="./css/index.css" media="screen">
//通过mdeia指定媒体类型及条件来区别引入css文件
<link rel="stylesheet" href="./css/index.css" media="screen and (min-width:300px)">style内联样式media指定媒体类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14//通过mdeia指定媒体类型来实现区别当前style是否生效
<style media="screen">
body{
background-color: antiquewhite;
}
</style>
//通过mdeia指定媒体类型及条件来实现区别当前style是否生效
<style media="screen and (max-width: 300px)">
body{
background-color: antiquewhite;
}
</style>style内通过@media实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14//指定媒体类型下的{}内样式生效
<style>
@media screen {
body{
background-color: antiquewhite;
}
}
</style>
//只在IE8下生效
<style>
@media \0screen {body { background: red; }}
</style>
rem适配方案
让⼀些不能等⽐⾃适应的元素,达到当设备尺⼨发⽣改变的时候,等⽐例适配当 前设备。
使⽤媒体查询根据不同设备按⽐例设置html的字体⼤⼩,然后⻚⾯元素使⽤rem 做尺⼨单位,当html字体⼤⼩变化元素尺⼨也会发⽣变化,从⽽达到等⽐缩放的适 配。
公式:页面元素的rem值=页面元素值(px)/(屏幕宽度/划分的份数)
屏幕宽度/划分的份数就是htmlfont-size大小
cssrem
可以自动从px转换为rem
具体步骤
设置里面找cssroot 将cssrem.rootFontSize修改为当前所需要的font-size
Echarts
使用Echarts
- 安装开发依赖Echarts
1
npm install echarts --save
- 在main.js中全局引入
1
2
3// 引入Echarts
import * as echarts from 'echarts'
Vue.prototype.$echarts = echarts - 进行引用
注意用$ref操作dom元素1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59<template>
<div>
list
<div ref="myechart" style="width: 600px; height: 400px"></div>
</div>
</template>
<script>
export default {
mounted() {
this.setChart()
},
methods: {
setChart() {
var myChart = this.$echarts.init(this.$refs.myechart)
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {}, // 字体悬浮
legend: {
data: ['销量']
// 各种线的总名字名字(图例组件)
},
grid:{
left:'',
right:'',
bottom:'',
containLable:'' // 此值为布尔值 改为false时会溢出并且隐藏左侧标签
}, // 直角坐标系内绘制网格
xAxis: {
boundaryGap:// 布尔值 坐标两侧留白策略当设置为true时,刻度只是作为分割线
data: ['衬衫', '羊毛衫', '雪纺衫', '裤子', '高跟鞋', '袜子']
},
yAxis: {},
series: [ // 系列列表
{
name: '销量', // 用于tooptip的显示,legend的图例筛选变化
type: 'bar',
stack:'销量' ,// 数据堆叠,如果设置相同值,则会数据堆叠
// 第二个数据值=第一个数据值+第二个数据值
// 第三个数据值=第二个数据值+第三个数据值
// 将stack去掉或者使用不同的值则不会发生数据堆叠
data: [5, 20, 36, 10, 10, 20]
}
]
}
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option)
}
}
}
</script>
<style lang="" scoped>
</style>
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true